
In this article we describe how Ceph Object Storage is configured in DKP, its architecture and some tips on how to troubleshoot issues.
In DKP 2.4 (and newer versions), the Object Storage used by the DKP logging and backup stacks (Grafana-Loki and Velero) is provided by Ceph. To deploy, manage and monitor Ceph in DKP, the Rook-Ceph operator is used.
Components
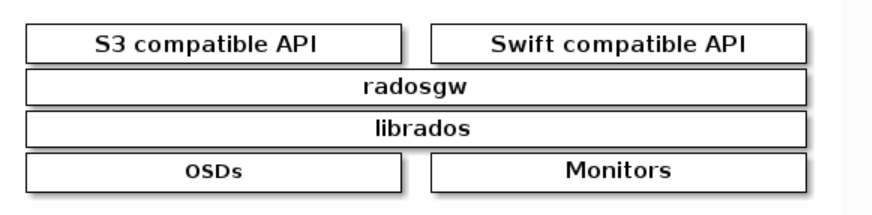
Object Storage Daemons (OSD): Ceph OSDs store data on behalf of Ceph clients. Additionally, Ceph OSDs utilize the CPU, memory and networking of Ceph nodes to perform data replication, erasure coding, rebalancing, recovery, monitoring and reporting functions.
Monitors: ceph monitors maintain the maps of the cluster state, including the monitor map, manager map, the OSD map, the MDS map, and the CRUSH map. It tracks active/failed cluster nodes, cluster configuration, and information about where the data resides and also manages authentication. Ceph clients retrieve a 'Cluster Map' from a Ceph monitor, bind to a pool, and perform input/output(I/O) on objects within placement groups in the pool. In DKP, the Ceph Cluster is configured to deploy 3 instances of the monitor.
Managers: The Ceph manager daemon runs alongside monitor daemons to provide monitoring and interfacing to external monitoring and management systems. It maintains detailed information about placement groups, process metadata and host metadata in lieu of the Ceph Monitor. The Ceph Manager handles execution of many of the read-only Ceph CLI queries, such as placement group statistics. It enables dashboarding capabilities as well.
Ceph Object Gateway (also known as Rados Gateway, RGW): is an object storage interface built on top of librados to provide applications with a RESTful gateway to Ceph storage clusters.
Important concepts and architecture
In DKP 2.3 and older versions, Grafana-loki and Velero were using minio as storage backend to persist data. Starting with DKP 2.4, Ceph is used as the object storage backend.
Grafana-loki and Velero communicate with the Rados Gateway daemons (radosgw) via a service with the name “rook-ceph-rgw-dkp-object-store” in the kommander namespace. The radosgw is an HTTP server designed to interact with the Ceph storage cluster and provides an interface that is compatible with Amazon S3. Data coming from Grafana-loki and Velero is persisted by the OSD daemons after passing through the radosgw.
How is the Rook-Ceph-Cluster deployed in DKP by default?
In DKP, the rook-ceph-cluster is deployed as a PVC-based cluster which means that Ceph cluster components will store its persistent data on volumes requested from the default storageclass.
How monitors and osd daemons consume the storage is controlled by how volumeClaimTemplates are defined in the CephCluster resource. By default, 3 replicas of the monitors are deployed that consume 10 GiB each and the volumes are mounted into Pods as a directory (volumeMode: Filesystem). On the other hand, 4 replicas of the osd daemons are deployed by default, consuming 40 GiB each and the volume is presented into a Pod as a block device, without any filesystem on it. This is the reason raw storage is required to deploy a CephCluster in DKP. In the VolumeClaimTemplates storageclass are not defined, therefore the default storageclass is used.
In pre-provisioned clusters, the default storageclass is localvolumeprovisioner which only consumes storage from formatted disk mounted at the path /mnt/disks/XXXX-YYY
Common issues encountered when deploying Ceph Object Cluster in DKP
Monitor clock skew: Keeping time in-sync across nodes is critical because the Ceph monitor consensus mechanism relies on a tight time alignment. If time is not in-sync across the nodes where the monitor pods are deployed, the cluster will show a HEALTH_WARN if you check the cluster status with the command:
kubectl -n kommander get cephcluster dkp-ceph-cluster
NAME DATADIRHOSTPATH MONCOUNT AGE PHASE MESSAGE HEALTH EXTERNAL
dkp-ceph-cluster /var/lib/rook 3 6d4h Ready Cluster created successfully HEALTH_WARN
And the status section will report that the time is not in-sync.
status:
ceph:
capacity: {}
details:
MON_CLOCK_SKEW:
message: clock skew detected on mon.c
severity: HEALTH_WARN
Not enough disks available to persist data: in DKP, osd daemons storage is presented as block storage without a filesystem. When raw storage is not provided, the status of the cluster will report the following:
TOO_FEW_OSDS:
message: OSD count 0 < osd_pool_default_size 3
severity: HEALTH_WARN
If the operator checks the osd-prepare pod logs, it will find how osd fails preparing any disk because there is no raw storage:
2023-03-24 23:10:29.399288 I | cephosd: 0 ceph-volume raw osd devices configured on this node
Issues rebuilding the Rook Ceph cluster due to pre-existing data from a previous deployment: when trying to rebuild the Ceph cluster, if the raw disks used by the osd nodes to persist its data contain data from a previous cluster, they will refuse to use the disks, and the following message is encountered in the logs of the rook-ceph-osd-prepare pod:
2023-07-07 21:58:46.246651 I | cephosd: skipping osd.2: "9cc588de-61fa-4d2b-9f1c-bb3b9782631f" belonging to a different ceph cluster "6b780502-f4bc-48a7-a881-4e382e7138e2"To fix this issue, a cleanup policy can be configured so when the Ceph cluster is deleted. The policy tells the Rook-Ceph operator to automatically delete the data on hosts. The following command should be executed to path the Rook-Ceph cluster and set the cleanup policy:
kubectl -n kommander patch cephcluster dkp-ceph-cluster --type merge -p '{"spec":{"cleanupPolicy":{"confirmation":"yes-really-destroy-data"}}}'
To confirm that the policy was configured correctly, this command may be executed:
kubectl -n kommander get cephcluster dkp-ceph-cluster -ojsonpath='{.spec.cleanupPolicy}'
PLEASE NOTE THAT DATA WILL BE PERMANENTLY DELETED when this cleanup policy is configured.
For additional information on how to clean up after a cluster removal please refer to this article.